|
“德语文献档案”简介
主题模型的优势是能够对海量文献进行高效率的分析。这里涉及到两个问题。
首先,“海量”是多少?Paper Machines是另一款可以进行主题模型分析的工具,其使用手册上注明,成功进行主题模型的下限是50份文献。(12)毫无疑问,过少的文献,我们完全可以直接阅读,获取有效信息的准确率一定高于机器识别。50份文献也是一个略指,并没有对每份文献的具体字数进行说明:实际上,将文献段落划分为不同文档,会影响主题模型输出的结果(虽然可能仅仅是某些词汇的改变)。
其次,什么样的文献能够进行主题模型分析?由于主题模型需要计算机对文字进行识别,所以需要把纸质文献转化为数字文档,即要对文字资料的图像文件进行识别处理(即所谓光学符号识别,Optical Character Recognition,简称OCR)。但我们知道,OCR的错误率是无法回避的问题,特别是对历史文献而言,OCR的输出结果总是差强人意。我们在本文使用的文献集中在18世纪,都是用花体字(Fraktur)印刷,转换出来的纯文本更是错误频出。对OCR文档进行清理,必要时用正则表达式(regular expression)提高工作效率,也是我们进行主题模型分析的准备步骤。
实际上,这两个问题都指向了文献数字化的状况。可以毫不夸张地说,文献的数字化,是开展数字人文研究的前提。作为史学研究者,我们或许更能体会何谓巧妇难为无米之炊,史料就是我们研究的依据;没有经过数码化处理的史料,等同于史学研究无米下锅。在这个意义上,建立史料的电子数据库,是一项基础设施建设。虽然它在客观上加剧了文献爆炸的事实,导致信息量太多以至于无法消化(too much to know),(13)但却是“数字史学”研究展开的第一步。
西方学界很早就意识到了这点。本文研究使用的数字文献,就受益于数字化基础设施建设的先期成果。我们的主体文献来自“德语文献档案”(Deutsche Textarchiv,简称DTA),是一个涵盖了从15世纪到20世纪初跨度达500年的德语文献数据库,当前收录的文献近1800件,文献类型包括书籍、报纸等,并在不断扩充。(14)“德语文献档案”其实是欧盟范围内CLARIN的一个子项目。CLARIN的全称是“通用语言库与技术基础设施”(Common Language Resources and Technology Infrastructure),其宗旨是对人文社会科学领域的语言材料进行归档与数码处理,实现资料共享,推进学术研究;各个欧盟成员国都有相应机构负责搭建各自语种的数据库,德国建立德语文献资料库的成果之一就是DTA。(15)
本文集中分析“德语文献档案”收录的1700-1800年间共计644件文献,字符数总量近3000万。这个时间段的划分,是由“德语文献档案”数据库的特性决定的。“德语文献档案”收录的德语文献有多个来源,(16)其原则不是为了穷尽某个年份的文献,而是要兼顾学科的全面与版本的首创。虽然数据库收录的文献跨度达500年之久,但从图2可以看出,文献数量的年代差异非常明显。1700年之前的文献相对较少,1800年之后的文献明显增多。根据主题模型的原理,过少或者过多的文献都会左右结果的输出,影响我们的分析;纵观整个18世纪的文献,既有康德、席勒、洪堡等重要历史人物的作品,也有被历史湮没的小人物的文字,甚至匿名者,虽然收录的文献仅仅是这个时代所有文献的很小一部分,但它们极具代表性,能够让我们比较全面地探寻时代面貌。另外,选择相对较小的文本容量,主要是考虑到能够与人工阅读对照分析,方便我们对主题模型的有效性进行评判。 
图2 文献的年代分布
600多份文献达到了运用主题模型工具的标准。这些文献的长短参差不齐,既有阿诺德(Gottfried Arnold)涉及教会史的大部头,(17)单篇就有10万字之巨;也有仅仅只言片语的宣传单。(18)需要指出的是,文献的统计单位以其原始形态为依据,即一部书记为一份,多卷本的书每卷单独计数,至于下文提到的报纸,以合订的一期为一份。在我们的分析中,每份文档被视为最小的研究单位。对于内容庞杂的单个文献之所以没有按照章节继续划分,是因为进一步的切割会破坏专著的语义完整,在返回原文进行细读分析时发生错位。
主题模型的运用与分析
LDA主题模型是十多年前提出的概念,其间不断有新的工具被开发出来。我们在本文主要采用具有图像界面的MALLET。实际上,现在被人文学者用来进行主题模型分析的Paper Machines以及Tethne等工具,都内置了MALLET的内核,它们在后台的算法基本相同。
主题模型的工作原理虽然不要求使用者事先对文献内容进行了解,但为了让输出的结果为人类理解,并被用作进行定性分析的材料,需要设置一些参数。其中一个重要参数是想让机器演算出多少主题,并用多少关键词进行表达。(19)考虑到“德语文献档案”文献类型的多样性,以及文献大小的巨大差异,我们将主题的数量确定为40个,每个主题用20个词进行表达。将全部644份文档导入程序之后,我们得到了一个完整列表。本质上说,拟合出来的主题复原了18世纪德意志的历史画面与精神世界,涉及了广阔的内容。它是没有任何人为因素参与的场景重建,呈现出来的形态令人瞩目。(20)
A.“德语文献档案”的整体状况
从某种意义上说,主题模型就是将总量达几千万字符的文献,浓缩到用800个主题词去理解。仔细观察全部40个主题的词群,我们发现有一些词汇在不同主题频繁存在。这或许是一个从整体上理解“德语文献档案”的指标。我们可以用文字云的工具,统计主题词的频率,得到可视化的结果(图3)。  图3 主题词的文字云
文字云透露了一些信息。在全部主题中,诸如Menschen(人)、Wasser(水)、Art(艺术)、Lieb(爱)等词汇高频率出现。我们可能会认为,这些关键词大概反映了18世纪的某种时代风貌,即对自然与人文的关注。这个判断也与既有的研究成果不谋而合。许多传统研究者提出,德意志文化存在“自然崇拜”的主题,自然景观被赋予了崇高的意味,而其中流露出宗教虔敬的特质则为早期浪漫主义的出现提供了养分。(21)当然,仅凭几个关键词就引申出整个18世纪的时代精神,这种推断在逻辑上可以存疑;另外,这些词本来就是德语中常用的词汇,如果没有上下文的语境,它们并不能提供更多的所指。对于文本分析而言,关键词的文字云功能有限,正如有学者强调的那样,在人文学科的研究中,文字云只不过提供了漂亮的装饰而已,(22)对于研究者开展有营养的文本分析远远不够。为此,我们需要对各种主题进行更加精细的解读。
首先,我们可以对这40个主题再进行分类。通过梳理不同主题,我们发现有些主题虽然由不同的词群构成,但在讲诉具有相关性的故事。照着这个思路,我们将40个主题划分成了12个大类: 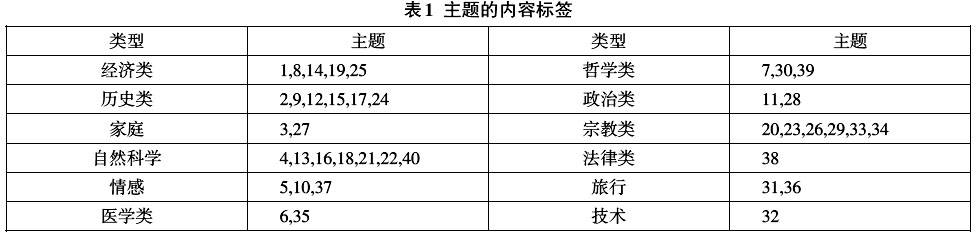 这个主题标签要比文字云更能说明问题,至少有两个非常明显的特征。
(责任编辑:admin) |