|
内容提要:主题模型是新近开发出来的研究方法,对于拓展数字人文的研究路径非常有价值。LDA是主题模型算法之一,将它运用到“德语文献档案”收录的1700-1800年间的文献,在归纳、分析文本的主题后,对主题模型方法的有效性进行评判。主题模型的演算结果让我们对18世纪德意志精神世界有了更加立体的认知:18世纪的作者具有强烈的历史意识,对知识体系的构建异常积极,小说受追捧与公共领域的兴起密切相关,宗教启蒙是时代主题。这些结果表明,启蒙运动具备多重面相。在历史研究中需要将以主题模型为代表的远距离阅读与细读有机结合起来,才能够得到更具说服力的研究成果。主题模型作为一种文本挖掘的方法,仍然存在改进的空间,而这种进步需要人文学者与计算专家的通力合作。这也是数字人文继续发展的必由之路。 关 键 词:数字史学/主题模型/德意志/启蒙运动/远距离阅读 基金项目:本文系国家社科基金青年项目“18世纪德意志的民众启蒙”(项目号:11CSS011)的阶段性成果。 作者简介:王涛,历史学博士,南京大学历史学院副教授。 数字史学(digital history)在西方学界方兴未艾,国内学者近年来也开始涉足。除了必要的理论探讨外,①史料型数据库建设是主要的成果呈现形态,而有历史特质的个案研究基本上以量化历史的面目出现,用数据库方法梳理观念史的研究以对关键词频的统计为依据。②数字史学当然不能止步于数据库的建设,量化历史或者词频统计的方法也不是数字史学的全貌。某种意义上说,历史研究的史料除了容易量化的数据外,更多是无法量化的文本,因此对数据库进行有效的信息提取与可视化呈现,才是数字史学的核心价值。先行一步的西方学者已经在使用主题模型(Topic Modeling)的方法对大规模文献进行数据挖掘,③拓展了数字人文(Digital Humanities)的研究路径,在史学研究领域,也有值得期待的可能性。本文将在关于德意志启蒙运动的研究实践中使用这种工具,并结合具体案例对其有效性进行评判。 主题模型的基本概念 手头有近700份文献,字符数在3000万左右,我们用什么方法在最短的时间内了解文献的整体面貌,并对文献内容进行整理?传统的方法是让不同的人同时阅读,做读书笔记,然后分享阅读成果,最终整合成一份读书报告。这种合作阅读(collaborative reading)的方式,通常被学者们用来处理庞杂的文献资料。它能够提升搜集信息的效率,④但也具有明显的劣势:它基于多人协作,处理信息的标准因人而异,让内容整合的客观性大打折扣。 更重要的是,这种传统的方式是一种直接的(direct reading)、近距离的(close reading)的阅读,处理信息的容量非常有限。正如克雷恩(Gregory Crane)在2006年提出的那样,“你怎么处理100万册的图书?”⑤在信息爆炸的网络时代,更有大量有效信息淹没在无关文献的海洋,人力的局限性在这里暴露无余。为此,文艺理论家莫莱蒂(Franco Moretti)曾经提出“远距离阅读”(distant reading)的概念,⑥其初衷实则沿袭了合作阅读的方式。专注机器学习与自然语言处理的专家,设计出“主题模型”的算法,能够在无须人工参与的前提下发现和归纳文本的主题内容。这种统计模型工具用机器阅读的形式兑现了远距离阅读的理念,为解决文献增量超出人类理解极限的状况找到了出路。 主题模型的工作原理立足于人类的写作习惯。写作者在创作文本时,都会预设若干主题。为了凸显某个主题,作者会在遣词造句时调用具有相关联的词汇,在主题模型的术语中,这些具有相关性的词汇被称为“词群”(bag of words)。举个例子,歌德在构思《少年维特之烦恼》(Die Leiden des jungen Werthers)时,⑦会设计不同主题,并用不同的文字展现出来。作为一部爱情小说,“爱情”(Liebe)一定是绝对的主题,但歌德也不会排斥对其他主题的描述,否则小说的可读性降低,对社会的描述也会非常扁平化。因此“自然”(Natur),“艺术”(Kunst)以及“社会”(Gesellschaft)等,也是可能的主题内容。为了描绘这些主题,歌德在写作中会调动相应的词群,例如,在描绘维特令人心碎的爱情时,一定会出现高频率地出现“Liebe”(爱情)、“Hertz”(心)等,也会有“umarmen”(拥抱)、“küssen”(吻)等,或者频率较低的“ewig”(永恒)、“morgen”(明天)等词汇。其他主题也有类似的词群以及频率。基于这样的创作习惯,如果我们能够统计词群,就能够把握与之对应的主题,进而了解整部文献的内容。 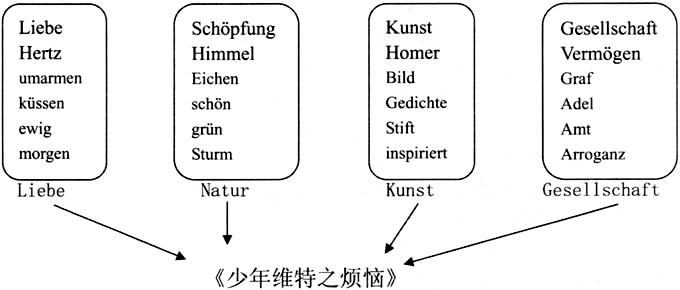 图1 歌德之维特的主题创作 在上述思路的指引下,布雷(David Blei)、吴恩达和乔丹(Michael Jordan)于2003年提出了“隐含狄利克雷分布”(Latent Dirichlet allocation,简称LDA),⑧成为主题模型最常用的算法。LDA通过特定公式计算词汇出现的频率,并将相互关联的词汇作为结果输出。这种模型是一种无监督学习的算法,具有刚性的客观性,即事先不需要研究者对文献内容有任何了解,也不需要进行人工标注、设置关键词等主观处理,而完全由电脑程序自动完成对文献主题的归纳。主题模型试图用数学框架来解释文档内容,这种做法看似同人文学科的习惯并不兼容。但是,LDA输出的结果是一组有意义的词群,而非纯粹的统计数据,人文学者能够使用这些词汇进行定性分析,证实或者证伪一些猜测,⑨将定量统计的客观与定性描述的开放充分结合起来,所以这个方法在人文学科领域极具应用的前景,特别是对动辄数以万计的文献来说,主题模型的计算能力非常诱人。⑩ 基于LDA的理念,计算机专家迈克卡伦(Andrew McCallum)写出软件MALLET,让归纳整理文献主题变成简单的命令录入,开始被人文学者广泛使用;(11)特别是在纽曼(David Newman)和同事用JAVA开发出图像界面的主题模型工具套件(Topic Modeling Tools,TMT)之后,使用者甚至不需要了解繁琐的命令符,进一步降低了应用门槛,让主题模型成为人人能够上手的工具。 (责任编辑:admin) |