|
三、数据、变量与模型 (一)数据来源 本文所使用的数据来自国家卫生计生委组织的2016年全国流动人口动态监测调查,该调查于2016年5~6月在全国31个省、***、直辖市和***生产建设兵团(不含港澳台地区)进行,调查对象为15岁及以上跨县、市流动的人口。(17) 鉴于本文的研究目的,我们从总样本中剔除了学生、军人、家务劳动者、退休、丧失劳动能力以及没有准确回答自己就业状况的受访者,最后得到样本139054人,包括少数民族流动人口10558人,占比为7.59%,并覆盖了我国绝大部分少数民族。其中回族和壮族流动人口的比例最高,分别占少数民族样本的23.55%和14.02%;接下来依次是藏族、苗族、满族、土家族、维***、蒙古族和彝族,所占比例均处于4%~10%之间,来自其他民族的流动人口比例均低于3%。 (二)变量界定与描述性统计 1.因变量。根据劳动经济学的基本概念以及本次调查的问卷设计,我们将受访者的就业状况分为四类:雇员、雇主、自营劳动者和失业。从表1中可以看出,少数民族流动人口的就业状况具有明显的特点,他们以雇员、自营劳动者形式就业的比例分别显著高于和低于汉族流动人口,雇主的比例在少数民族和汉族之间并不存在显著差异。而需要特别注意的是,少数民族流动人口的失业率不仅显著高于汉族,并且在数值上几乎是后者的两倍,这是已有的研究没有注意到的。 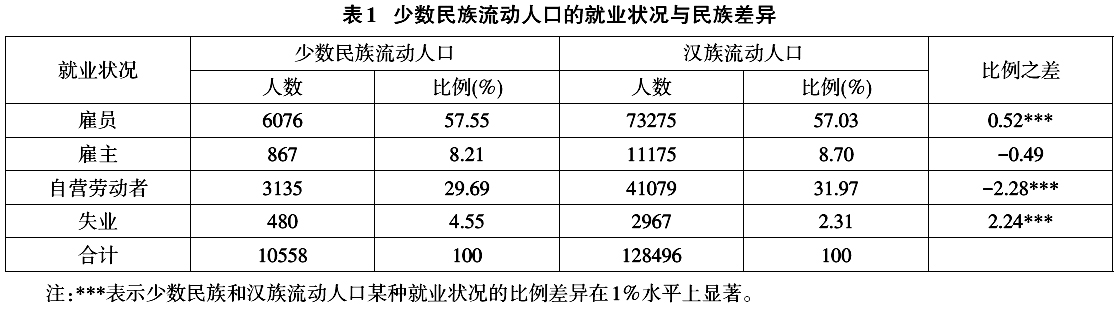 2.自变量。首先是民族状况。本文将其设置为虚拟变量,如果受访者为少数民族,将其赋值为1,如果是汉族,则赋值为0。其次,根据前文的理论分析,我们还从三个方面选择了影响流动人口就业状况的主要因素:一是个人情况,包括受访者的性别、年龄、户口情况等;二是人力资本水平,主要是指流动人口的受教育程度;三是流动特征,包括受访者的流动范围和流入地所在区域。 表2显示了上述主要变量的定义、赋值与描述性统计情况。 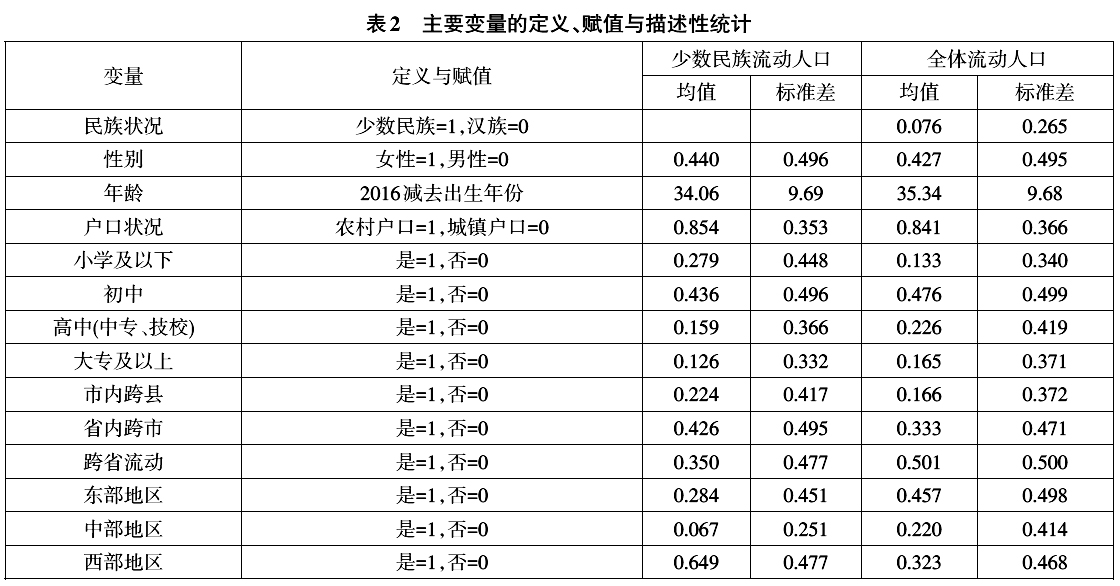 (三)计量模型与估计策略 为了对影响少数民族流动人口就业的状况的因素进行实证检验,本文在理论分析的基础上设定了如下计量模型。 首先,我们通过计量方程(1)检验民族变量对流动人口就业状况的影响。其中Eik表示流动人口i的就业情况k,根据前文的设定,k包括“雇员”“雇主”“自营劳动者”和“失业”等四种类别。Ethnic为民族状况虚拟变量,Z为就业状况的主要影响因素,在方程(1)中属于控制变量,其中包括个人情况、人力资本水平和流动特征等三个方面。 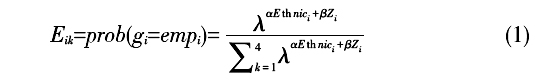 由于四种就业状况之间不存在明显的排序关系,因此本文使用Multinomial Logit模型对其进行估计。其中我们主要关心参数α的估计值。根据Multinomial Logit模型的特点,在估计前需要选取某一类就业状况参照组,将其系数标准化为零。本文以“雇员”方式作为参照组。民族变量的估计系数α反映了与雇员方式就业的流动人口相比,选择其他三种就业状况的倾向。 接下来本文将使用计量方程(2)进一步考察影响少数民族流动人口就业状况的主要因素及其方向,其中  表示少数民族流动人口j的就业情况k。由于方程(2)的估计对象仅限于少数民族流动人口,因此自变量中没有包括民族虚拟变量Ethnic,其余自变量与估计方法与方程(1)相同。此时,我们通过系数估计值γ的符号和显著性水平考察相关因素对少数民族流动人口就业状况的影响。 表示少数民族流动人口j的就业情况k。由于方程(2)的估计对象仅限于少数民族流动人口,因此自变量中没有包括民族虚拟变量Ethnic,其余自变量与估计方法与方程(1)相同。此时,我们通过系数估计值γ的符号和显著性水平考察相关因素对少数民族流动人口就业状况的影响。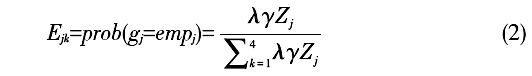 (责任编辑:admin)
(责任编辑:admin) |